
Emmis Voice AI Assistant
A real-time Swedish voice assistant built for the people digital services keep leaving behind, shipped as a live product with paid plans in place, on infrastructure she owns end to end.
Visit liveemmis.oneTL;DR
A live Swedish voice assistant for the people digital services leave behind. You open a phone browser, verify by SMS, and just talk, no app, sub-second replies, interruptible mid-sentence, and it remembers past conversations. Swedish-first speech in and out, self-hosted end to end on infrastructure she owns, designed and shipped solo.
The global digital infrastructure has quietly drawn a line, and on the wrong side of that line is a population large enough to fill a city. Banks closed their branches. Government agencies went app-only. Healthcare moved into BankID-gated portals. Family helps when they can; the rest of the time, the line is a wall. Emmis was built to give the people on the wrong side of that wall a way to ask their questions out loud, in Swedish, to something that actually answers, not a menu, not a chatbot, not a contact form.
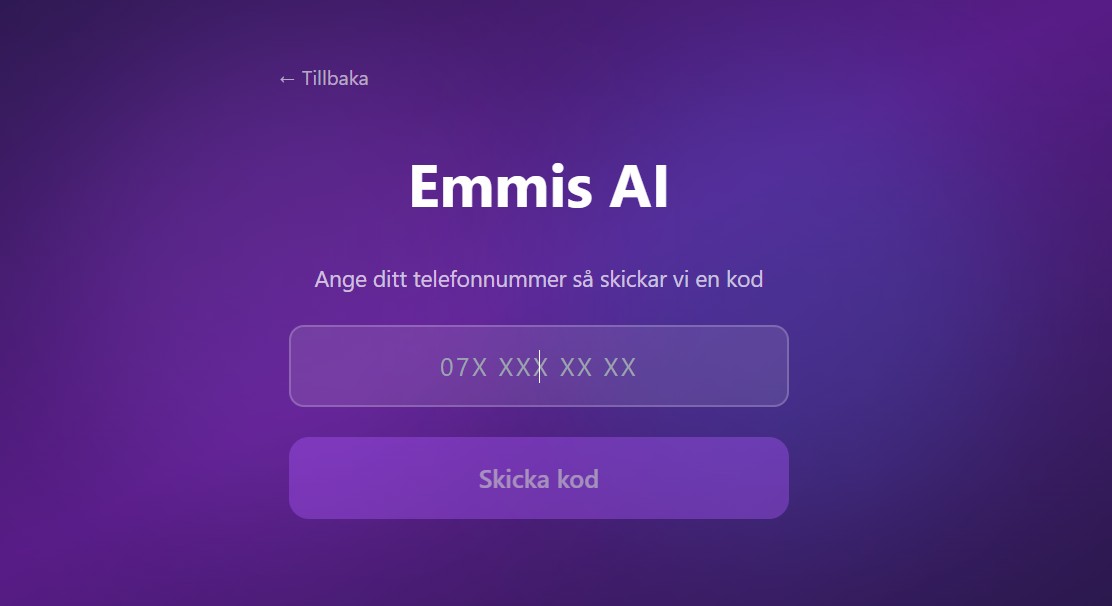
What it is concretely. A user opens a phone browser, navigates to emmis.one, verifies their phone number by SMS, and presses one button. From that point on, it is a conversation: speak in Swedish, hear an answer in Swedish, no screen to read, no menu to navigate, no app to install. The exchange is full duplex, Emmis can be interrupted mid-sentence the way a person can, and it remembers. Conversations that came before inform the ones that come after. A free tier exists so anyone can try without committing.
Validated quietly with the audience. Before broader release, Emmis ran through a small invite-only pilot with users from the target group. The findings were strong.
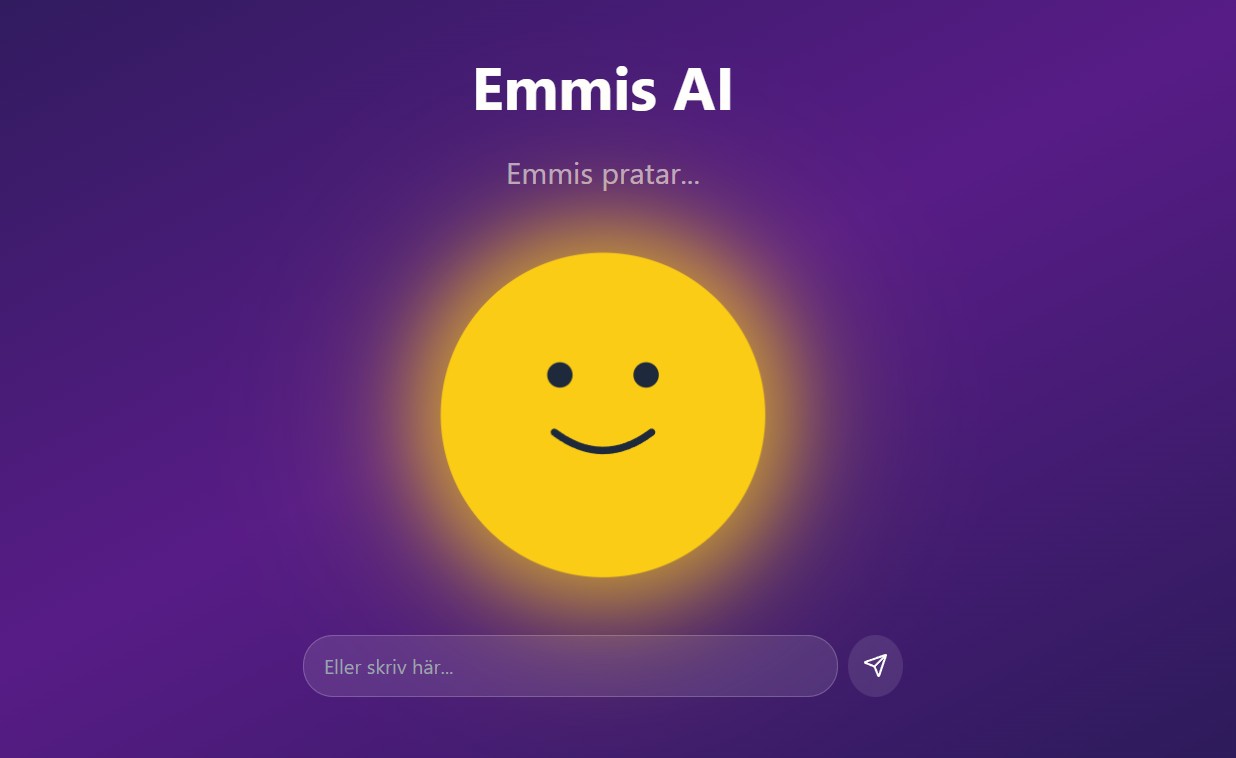
Real-time voice, not chat-with-TTS-stapled-on. The pipeline is end-to-end streaming. The user finishes speaking; speech-to-text transcribes; the language model starts emitting tokens; the TTS engine begins synthesising sentence-by-sentence the moment the first sentence is complete; audio chunks stream to the phone speaker as they are produced. Time-to-first-word is sub-second. The user can interrupt at any point, the system listens during playback, detects voice over its own audio, and stops mid-sentence to listen properly. That detail, barge-in, is what separates a real conversation from a system that feels like waiting for a robot.
Swedish-first, not Swedish-as-a-locale. Voice AI that ships Swedish as an afterthought has a dozen tells: anglicised intonation, mispronounced surnames, missed words on Skåne or Norrland speech, hallucinated transcriptions of background noise where none was spoken. Emmis is built around a Swedish-tuned STT and a Swedish-trained voice on the synthesis side, and the cleaning passes between them, noise filtering, hallucination guards, transcript validation, assume Swedish speech, not generic input. The result lands as Swedish from the first word. For the audience this product is for, that is not a polish detail; that is the entire experience.
Two models, one conversation. Different conversational registers want different model behaviour. A factual question wants precision and short, structured sentences. A bit of small talk on a Sunday afternoon wants warmth and natural turn-taking. Emmis dispatches between two models depending on the register of the turn, with sticky behaviour that prevents the system ping-ponging between styles inside a single conversation. The user does not see the dispatch. They feel it as the system answering in the right tone for the question they asked.
Memory between calls. Conversations summarise themselves. The summary lives in a per-user record, not a transcript dump, and the next time the user comes back, Emmis already knows roughly what was discussed, the recipe attempted last week, the question about pension paperwork that didn't get fully answered, the name of the cat. Continuity matters when the audience is the audience. The amnesia of treating every conversation as the first is what makes most consumer voice AI feel hostile to the people who need it most.
Self-hosted end to end. The product runs on a single European server. The backend is one Node.js service. The database is a local PostgreSQL container, backed up nightly with thirty-day retention. The frontend is a static bundle served by the same reverse proxy. No Supabase. No third-party admin platform. No cross-border data flow. Audit-grade session and transcript logs are kept locally. The architecture is deliberately simple, because complexity in a system that handles voice from elderly users is not a flex; it is a liability. Simple, self-hosted, owned.
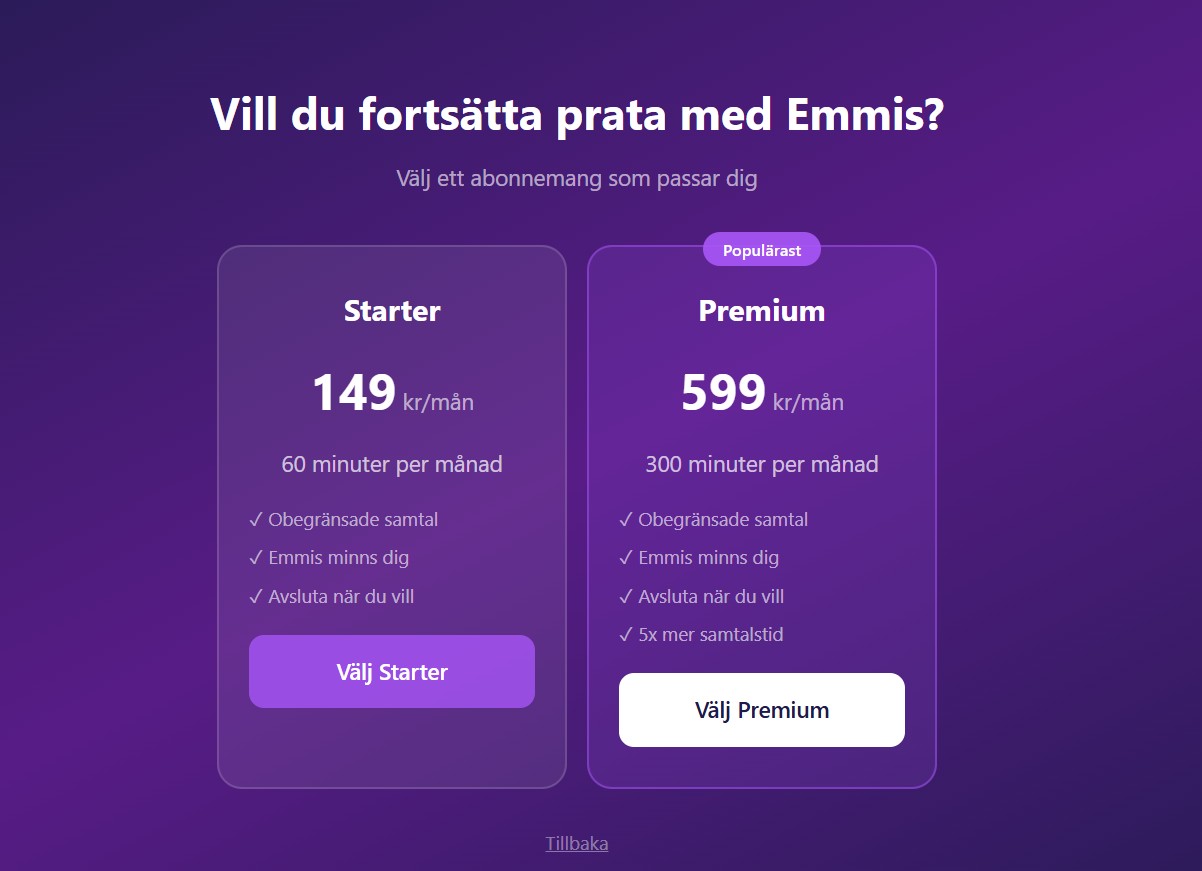
Live, with real users. Real conversations, in Swedish, with the people it was built for. The free tier exists so the family member helping their parent set things up can demonstrate it once before any commitment is made. The paid tiers are in place because shipping a genuinely useful service costs money to run, and pricing it honestly from the start is part of treating Emmis as a real product, not a demo that quietly disappears.
The usual pitch deck for AI accessibility shows a chatbot on a public-sector website that no elderly user will ever actually find their way to. Emmis is the version that gets used. It is a button you can press, a voice that answers you in your own language, and a memory that does not reset every time you call. Underneath that surface is a real-time voice pipeline, a two-model dispatch, a privacy-respecting self-hosted stack, and a designer who listened to her users when they told her she had the framing wrong. That last detail is the one the technology will not tell you, and it is the one that made the product work.
Questions about this work, or something like it?
Ask the agent