
Björn: Personal Health & Training Intelligence
A continuously-running personal health intelligence agent she designed and runs against her own body, twelve health domains observed, multimodal natural-language input over Telegram, bodyweight training designed against its own session history, domain science codified at the schema level.
TL;DR
A continuously-running personal health agent she designed and runs against her own body, observing twelve domains from nutrition and training to sleep, mood, and bloodwork. Plain-language input, typed or photographed, is parsed and written through a typed tool into a structured store with provenance on every row, and domain science is codified at the schema level so the agent cannot invent values. Daily and weekly check-ins fire on schedule, and a background scanner surfaces cross-domain drift.
Alfija advises C-suite executives on AI transformation, and wanted to know, viscerally, what it costs to put an AI agent into a continuous observation role on a single person, every day, for months at a stretch, across every health domain a clinician would ask about. Tracking her own body is the cleanest way to find out: real conversations every morning, real consequences every week, no client to escalate to. The point of Björn is not to lose weight. The point is the discipline of an agent that listens in plain language across nutrition, training, symptoms, sleep, mood, hydration, medications, and bloodwork, extracts structured data the way a careful clinician would write it in a notebook, and applies expert rules the same way every time, no matter how the day went.
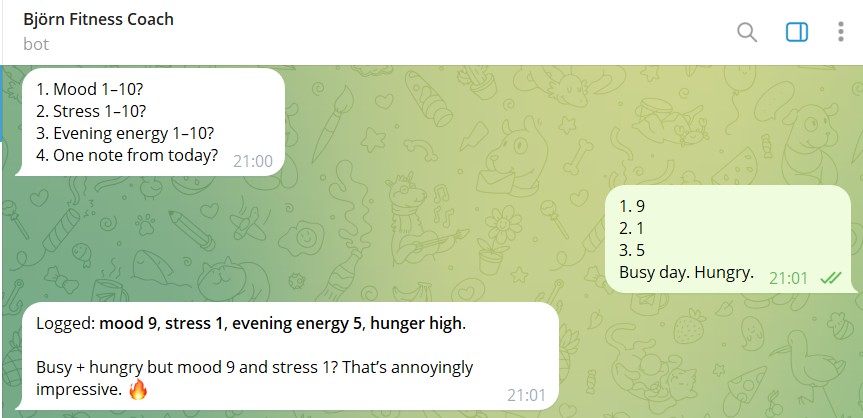
Twelve domains, one agent. Björn does not observe a single thing. The structured store covers nutrition (food, macros, FODMAP-pattern flags), training (planned and completed sessions with format, structure, and feedback), casual movement, weight, symptoms (gut, headache, fatigue, skin) on a 1–5 severity scale, hydration with caffeine attribution, supplements with dose, longer-lived medications with start and stop dates, lab bloodwork, daily check-ins covering sleep, mood, stress, energy and a free-form day note, and a Sunday weekly review with six reflection prompts. Twelve tables in total, plus a catch-all notes table for new categories that have not earned their own schema yet. The agent is the integrating layer across all of it, the same conversation surface for "had two coffees", "noticed gut flare after lunch", "12-minute EMOM, felt strong", and "weighed in this morning". One observer, one record, one place the cross-domain patterns can show up.
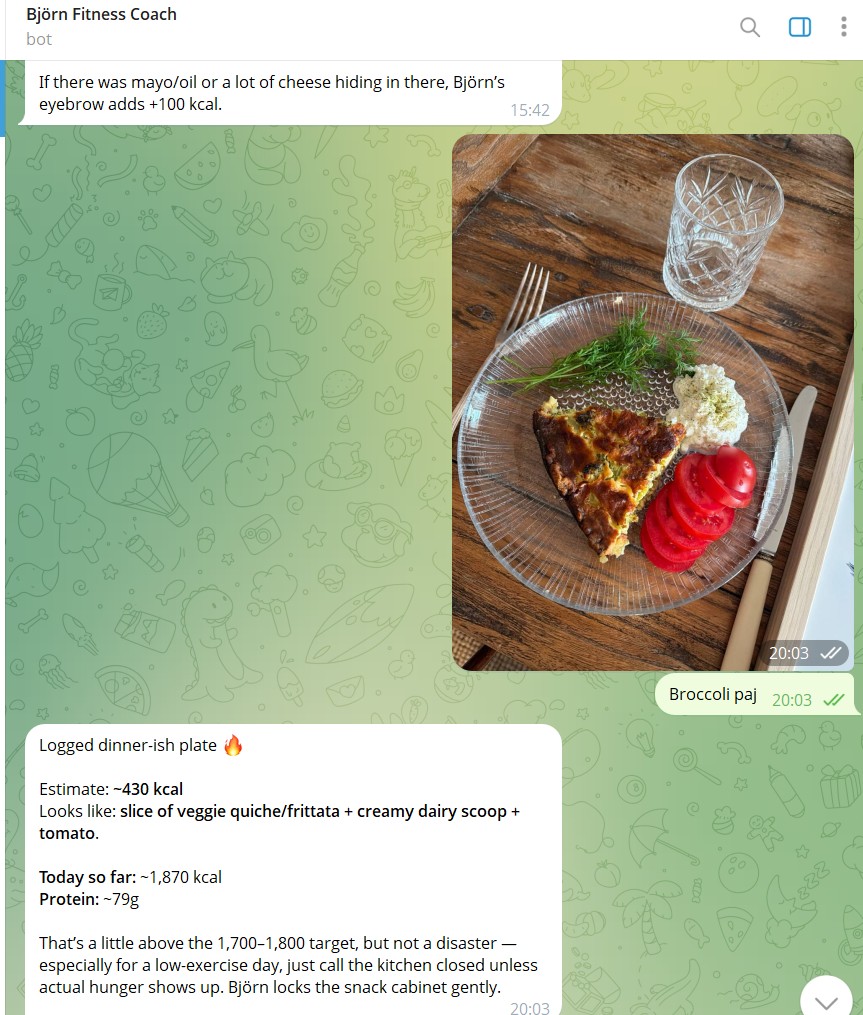
Natural language in, structured data out. Björn lives in Telegram. She sends messages the way a person actually speaks, "toast and coffee, the usual breakfast", "stomach acting up after lunch, maybe a 3", "did twelve minutes EMOM, felt strong". Björn parses each message, decides which structured event(s) it implies, and writes them into a SQLite database through a small JSON-in / JSON-out tool that exposes the database as a typed surface. The agent never touches the database directly, every write goes through the typed surface, every error returns a code, and every row carries a source field recording how the data got there: manual, voice, photo, estimated, looked-up, or auto. Provenance is structural, not optional.
Multimodal extraction, same row. A photo of a meal lands the same way a typed description does: Björn identifies the components, estimates kcal and macros, flags any FODMAP risks, sums against the day's running total, and writes a row with source='photo' so the next reviewer can see the entry came from image input rather than self-report. The agent has the same conversation about a slice of quiche as it does about a protein shake. The shape of the resulting row is the same; the difference is recorded in one column.
The schema is the architecture. The daily check-in is upserted one row per day, filled in as the day progresses. Everything else is append-only. Almost every column is nullable, because a real human reports partial information and demanding completeness is the surest way to kill a tracker. Scales are constrained at the database level, 1–10 for sleep, mood, stress, energy; 1–5 for symptom severity, so the agent cannot drift into invented ranges. New categories go into the catch-all notes table first; only after a category proves itself does it earn its own table. The schema codifies the discipline of know what you're tracking, know how you're tracking it, and don't pretend completeness you don't have.
Pinned check-ins, not a nag bot. Three cron-driven prompts fire as isolated agent turns: a morning check on sleep, an evening check on mood, stress, energy and a day note, and a Sunday weekly reflection with six prompts. Each prompt queries the database first and skips silently if the data is already there, Björn does not ask twice. A numbered-prompt convention ("1) sleep hours 2) sleep quality 1–10") parses predictably back into the right fields. The result is a continuous observation loop she does not have to manage: the agent shows up at the same time, asks the right thing, and is quiet otherwise.
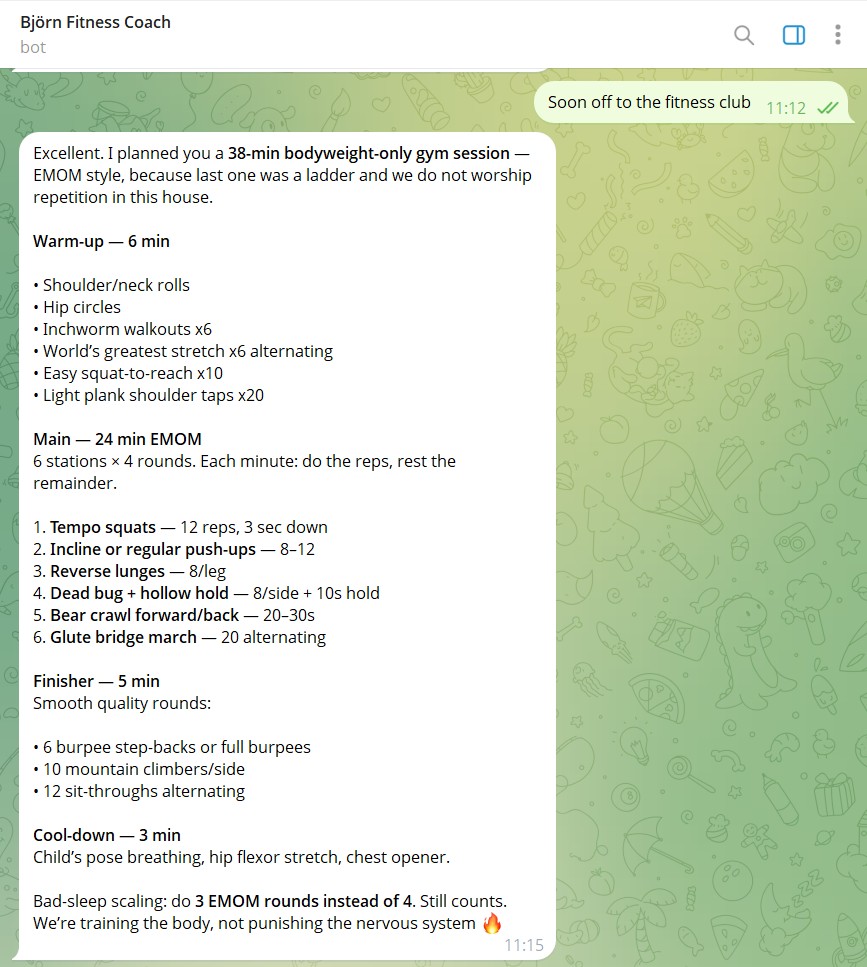
Domain science codified, not generic coach prompts. Calorie targets follow Pontzer constrained-TDEE rather than the additive-burn folk model most fitness apps still ship. FODMAP-pattern flagging is built into the food schema because her gut has an actual pattern, and a generic "low FODMAP" suggestion is not a substitute for tracking what was actually eaten. Workouts are bodyweight calisthenics only, with the equipment field constrained at the schema level so the agent cannot drift into gym-equipment programming she will not do. Each session is composed warm-up → main block → finisher → cool-down, with bad-sleep scaling rules baked in ("do 3 EMOM rounds instead of 4. Still counts. We're training the body, not punishing the nervous system."). The expert rules sit in the system prompt; the schema enforces them.
Variety enforced by querying its own history. Before designing a new workout, Björn queries the last five sessions and picks a format not used recently, EMOM, AMRAP, Tabata, Ladder, Circuit, Pyramid, Countdown, Superset. The rule exists because of one piece of feedback: "too similar structure, want more creativity". That sentence became a query. The agent does not remember the rule by being reminded; the rule is a SQL statement against its own training history.
Web-search-grounded estimates with provenance. When she mentions an unfamiliar food, supplement, or caffeine source, Björn fetches the data live and writes the row with source='looked_up' so any later review can see which numbers came from grounding and which the agent computed itself. Subjective ratings, mood, stress, perceived exertion, are never looked up; those are always her own call.
A pattern-scanner runs in the background. A separate scheduled job runs once a day across the structured store, looking for things the user is unlikely to notice in real time, drift between sleep quality and mood, FODMAP-pattern flares clustering around specific food categories, symptom-fatigue trends aligning with training intensity, hydration gaps that correlate with bad sleep. Quiet by default; surfaces only what is worth surfacing. The point of the database is not just to record events but to let cross-domain patterns become visible, which is the entire reason a single agent observing twelve domains is more useful than twelve disconnected tracking apps.
Memory holds insights, the database holds events. The agent's persistent memory file is short and stays short, recurring meals to copy verbatim, behavioural patterns, things to do differently next time. The twelve tables hold every event. That separation matters: the moment a memory file becomes a transaction log, it stops being useful as an instruction surface and the agent starts contradicting itself.
Why this lives in the AI portfolio and not the personal-projects drawer. Because it is a working answer to the question CIOs ask her every week: what does it look like when an AI agent observes a real human in a real environment, every day, for months, and what does the human actually do? It looks like a Telegram thread that does not nag, a database that fills in by itself, a coach that picks a workout format it has not run lately, and a quiet pattern-scanner that surfaces cross-domain drift. The split of labour between the agent and the human is the deliverable, the same way it is at AlgoAlfi, the same way it is at Emmis Company, applied here to a single person across every health domain a clinician would ask about, the one closest to home.
What you see when you open the chat is a friendly bear who asks the right questions at the right times and locks the snack cabinet gently. What's underneath is a typed extraction layer over twelve health domains, a constrained schema that records its own provenance on every row, a cron-pinned check-in pattern, a multimodal input loop, a daily pattern-scanner, and a set of domain rules grounded in nutrition science and training methodology that do not loosen because the day was hard.
Questions about this work, or something like it?
Ask the agent